
ComfyUI で FramePack を試してみる
少し前から FramePack という動画生成 AI が話題になっています。ローカルで実行でき、内容の破綻も抑えられるとか。すでに FramePack の派生もいろいろ誕生しているようですが、やっと手元の環境でも実行できるようになったので、まずは FramePack を実行するところまでをまとめます。
概要
- ComfyUI で生成できました
- GeForce RTX 2070 (VRAM 8GB) でも生成できました(注)
- 2 秒の動画を生成するのにおよそ 7000 秒、2 時間近くかかりました
注:確かにできますが、メモリ (VRAM ではなくシステムメモリの方) が 64GB 必要です。32GB だとエラーにはならないのですが画像が生成できません。
準備
メモリ増設
16GB x2 で 32GB 搭載していたのですが、同じく 16GB x2 を追加して合計 64GB にしました。メモリ増設をしなくても、エラーにはならないのですが出力される画像が真っ黒でした。また、処理の間 GPU がほとんど動かなかったので、おそらく処理がうまく走っていなかったのだと思います。
64GB にすると、OS 込みで 60GB 弱までメモリを使い、動画が生成されるようになりました。また、GPU もしっかり負荷がかかっているようです。そのため、メモリは 64GB 必要そうです。

モデルのダウンロード
ComfyUI での実装は ComfyUI-FramePackWrapper を使います。GitHub のページにも必要なモデルのリンクが貼ってあります。
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files から clip と vae 合計 3 ファイルを以下に配置します。
ComfyUI/models/clip/clip_l.safetensors
ComfyUI/models/clip/llava_llama3_fp8_scaled.safetensors
ComfyUI/models/vae/hunyuan_video_vae_bf16.safetensors
https://huggingface.co/Comfy-Org/sigclip_vision_384/tree/main からは SigClip をダウンロードして以下に配置します。
ComfyUI/models/clip_vision/sigclip_vision_patch14_384.safetensors
モデルはファイルが分割されたもの、1 ファイルにまとまっているものがありますが、今回は 1 ファイルの FP8 版をダウンロードし、以下パスに保存しました。
ComfyUI/models/diffusion_models/FramePackI2V_HY_fp8_e4m3fn.safetensors
ComfyUI の準備
ComfyUI を docker compose で構築する で用意した Docker Compose の環境を使います。ComfyUI のカスタムノードを追加する必要があるのですが、ComfyUI Manager からだとうまく追加できないので、コンテナ内のシェルから git コマンドを使って追加します。
コンテナ内のシェルから、
cd /ComfyUI/custom_nodes
git clone https://github.com/kijai/ComfyUI-FramePackWrapper.git
cd ComfyUI-FramePackWrapper
pip install -r requirements.txt
と実行し、必要なライブラリをインストールします。ComfyUI を起動済みであれば、ComfyUI Manager のメニューなどから ComfyUI を再起動します。そのうえで、
/ComfyUI/custom_nodes/ComfyUI-FramePackWrapper/example_workflows/framepack_hv_example.json
このファイルを、ブラウザを実行する PC にコピーして、ComfyUI から読み込みます。
生成
ワークフローを読み込むと、そこそこ大きなフローですが、確認や変更する点がありますので、それぞれ説明します。
1.VAE
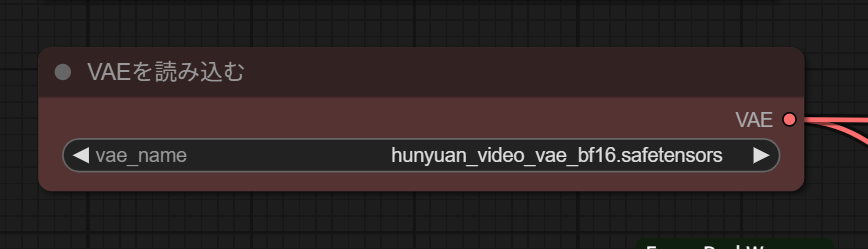
配置したファイルが認識されているか確認します。ファイル名が異なる場合は、一度クリックすると配置済みのファイル名が表示されるので、そのファイル名をクリックします。もしダウンロードしたファイルが表示されない場合は、配置場所に間違いがないか確認します。
2.CLIP

初期値でこうなっていると思いますが、こちらも念のため「clip_name1」と「clip_name2」をクリックして確認します。
3.SIGCLIP
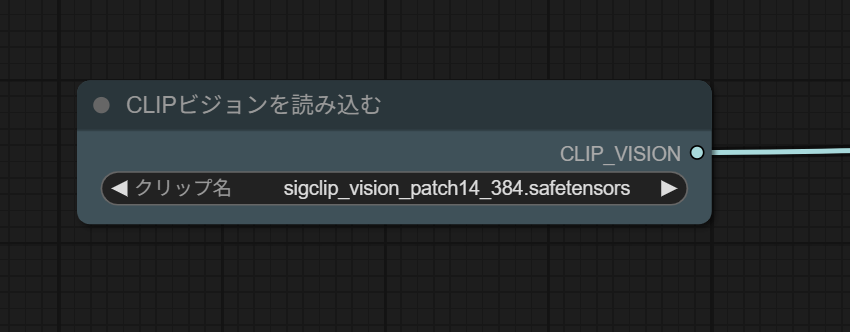
こちらも初期値でこうなっていると思います。
4.入力画像
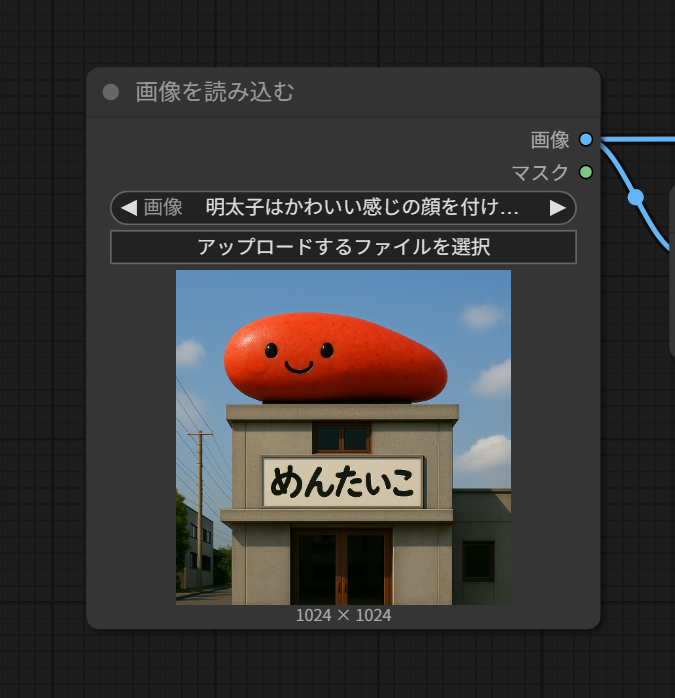
「アップロードするファイルを選択」をクリックして、動画の元となる画像ファイルを選択します。
5.モデル

こちらは初期値のパスが違うはずなので、「model」をクリックしてダウンロードして配置したファイル名に置き換えます。また、「base_precision」も初期値が bf16 になっていますが、RTX2070 は BF16 をサポートしないので、fp32 に変更します。
6.FramePackSampler

「total_second_length」は生成する動画の長さ (秒) です。まずは短めで実行して、問題なく生成できるかを確認してみるといいと思います。なお、1 秒にすると生成がエラーになってしまうので、エラーにならない最小の 2.0 にしました。
「embed_interpolation」と「start_embed_strength」は初期値だとエラーになるので、一度クリックしてそれぞれ liner と 1.0 を選択しました。
緑丸をつけた「生成後の制御」は、シード値をどうするかの選択です。初期値は fixed なので、複数回実行してもほぼ同じ動画が生成されると思います。試しに実行する場合はこのままでもいいですが、いろいろなパターンを試したい場合は randomize などに変更してもいいかもしれません。
7.VAEデコード
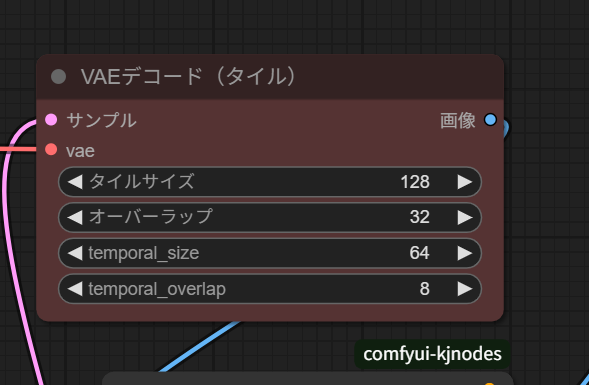
VRAM の大きさに応じて値を調整しないと、CUDA の OutOfMemory が発生します。VRAM 8GB の RTX2070 の場合は「タイルサイズ」を 128、「オーバーラップ」を 32 にすると出力できました。
8.Video Combine
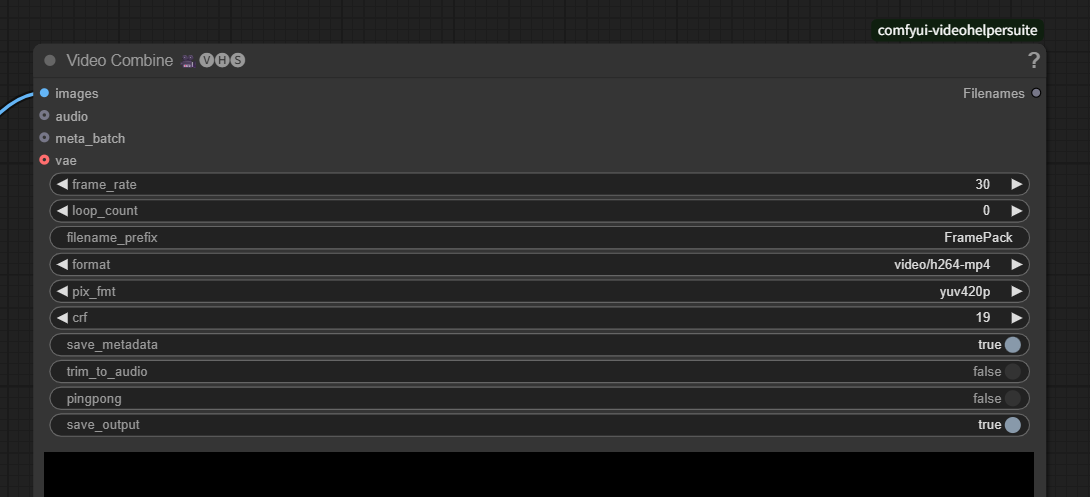
「save_output」を true にすると、出力イメージが自動的に ComfyUI/output に保存できます。
実行
ComfyUI でワークフローを実行すると、動画が生成されます。主には「FramePackSampler」で時間がかかる感じですが、前述の通り 2 秒の動画で 7000 秒程かかります。

生成された動画がこちら。
なんで・・・という感じですが、それでも RTX2070 が 7000 秒もフル稼働した結果なので・・・